Практические примеры использования
На этой странице мы будем рассказывать о практике использования программы в реальных условиях. Как показывает практика некоторые возможности программы не так очевидны, как нам бы того хотелось.
Как собрать максимум страниц из индекса Яндекса?
Если ваш сайт насчитывает больше 1000 страниц в индексе поисковой системы, то перед вами может встать непростая задача – а как же собрать все страницы? Давайте попробуем собрать максимум страниц!
Вариант 1. Если страниц вашего сайта до 2000. Тогда подойдет простой способ.
Переходим в вкладку программы «Яндекс», нажимаем на кнопку «Запустить», указываем адрес сайта в диалоговом окне и обращаем внимание на поле «Сортировка выдачи по». Выбираем любой вариант, например, по релевантности:

Запускаем парсинг. Ждем его окончания. Программа соберет все результаты и остановится. После этого нам надо запустить парсинг еще раз, сохранив текущие результаты. Нажимаем кнопку «Запустить» и выбираем иной метод сортировки, например, по дате:
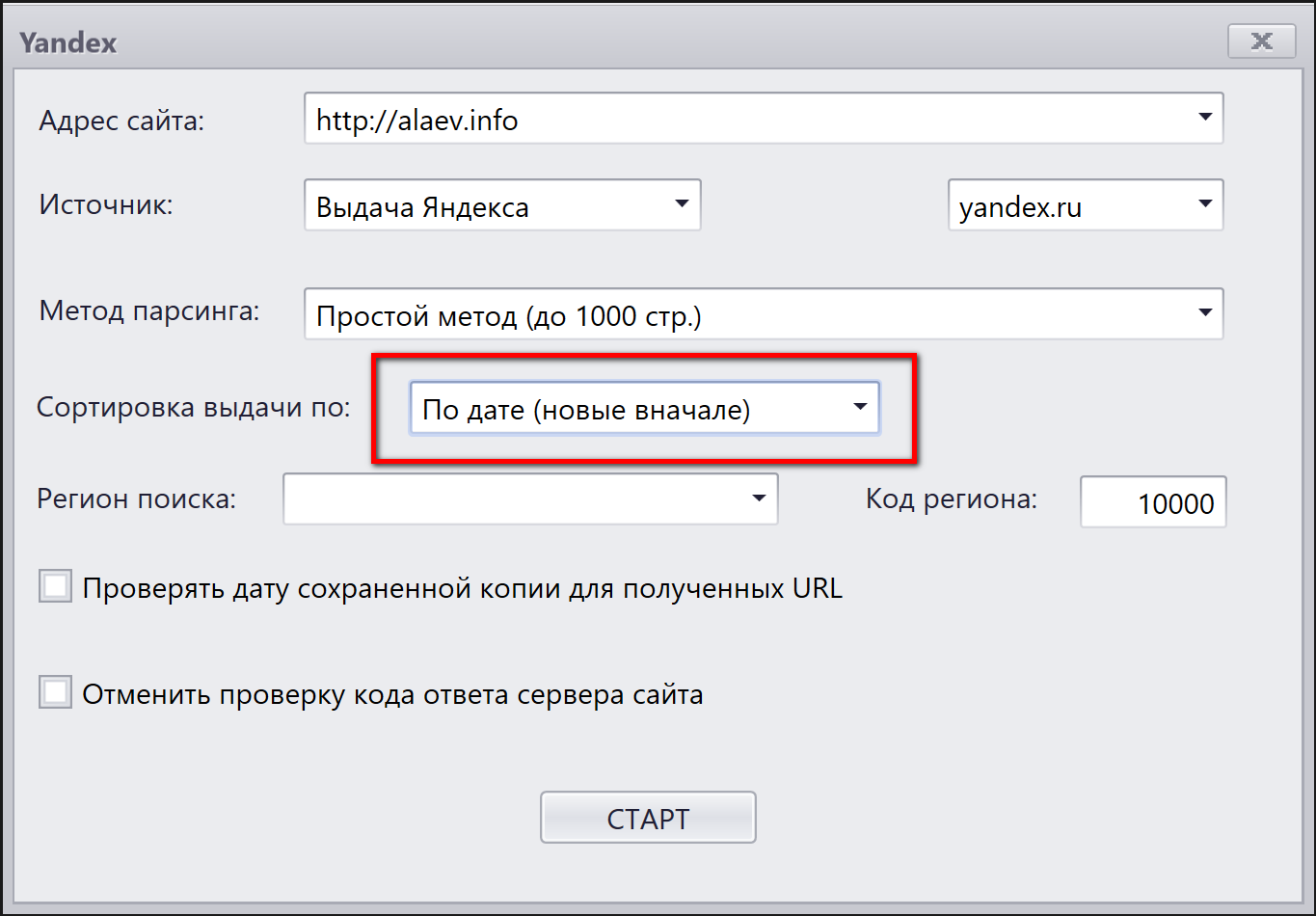
На вопрос программы об очистке проекта отвечаем отказом:
![]()
Начнется парсинг и программа соберет обязательно дополнительные результаты. В итоге вы получите до 2000 спарсеных результатов. Таким нехитрым способом мы обошли ограничение на 1000 результатов.
Вариант 2. Если страниц в индексе много, т.е. несколько тысяч или даже десятков тысяч. Для парсинга страниц из индекса для большого проекта необходимо полностью обойти сайт краулером. Это необходимо для построения структуры сайта.
Чтобы построить структуру сайта, дождитесь окончания парсинга, откройте вкладку сбоку «Статистика и структура», нажмите вкладку «Структура» и кнопку «Построить дерево». Можете не отмечать никак чекбоксы. После завершения процедуры вы увидите что-то подобное:
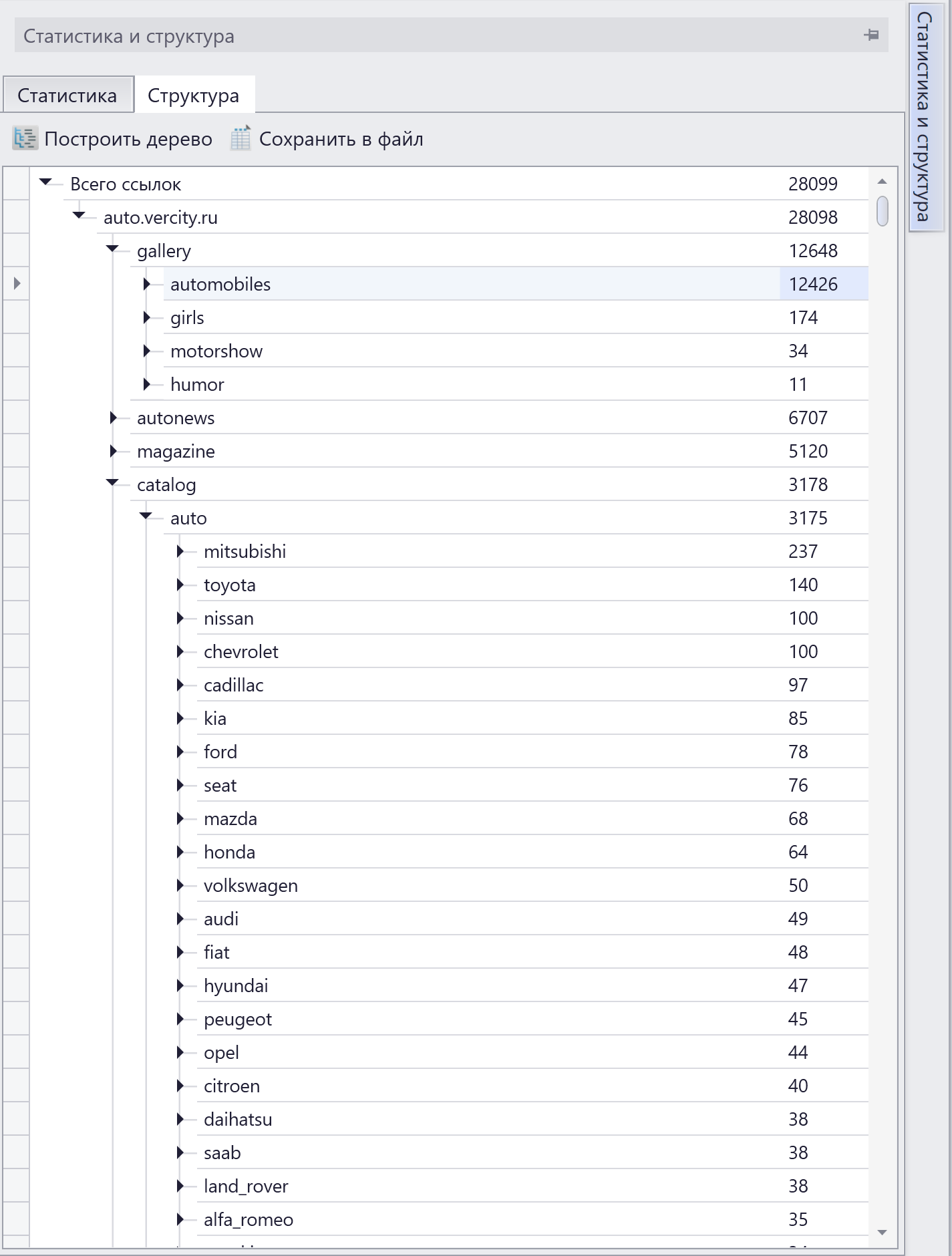
Это обычный раскрывающий древовидный список страниц сайта. Чем более разветвленная структура у вашего сайта, тем больше и проще нам удастся собрать страниц из индекса.
Теперь переходим во вкладку «Яндекс» и нажимаем «Запустить». Выбираем метод парсинга методом перебора и минимум запросов, вот так:

Стартуем. Программа будет задавать в Яндекс запросы согласно структуре, то есть не парсить все подряд от корня, а идти по вложенным каталогам, ограничивая выдачу. То есть, предположим, что у вас структура сайта делится на каталоги /news/, /catalog/, /gallery/ и /articles/ и в каждом по 900 страниц. Обычным методом бы мы собрали только 1000, ну, максимум 2000 страниц. А методом перебора мы соберем 900+900+900+900=3600 страниц. Принцип ясен!
А что такое «Метод перебора (более 1000 стр.)», спросите вы? Это жестокой и страшный метод, т.к. основываясь на структуре сайта, программа будет проверять на индексацию каждую отдельную страницу, попавшую в структуру. В процессе использования программы вы однажды заметите, как собрав структуру, на сайте обнаружится папка, в которой больше 1000 страниц, разворачиваешь и видишь их все. Чтобы проверить индексацию данного каталога надо обойти все это страницы индивидуально. Программа будет поштучно проверять все страницы. Честно говоря, не рекомендую использовать этот метод, он слишком затратный как по времени, так и по кол-ву запросов, даже если вы будете использовать сервис распознавания капчи (например, рукапчу), это встанет вам в кругленькую сумму.
Метод перебора с названием «Метод перебора (более 1000 стр.), минимум запросов» очень выгодный. Программа выделяет в структуре сайта каталоги и обходит только их, минуя единичные страницы. Если в каталоге более 1000 страниц, программа его разворачивает и ищет вложенные каталоги, если они есть, обходит их, если нет – берет основной каталог и парсит его, тогда для этого каталога будет собрано максимум 1000 страниц. Надеемся, этот принцип вам тоже понятен!